
Table of contents
Introduction
The Knowledge Grid is a software framework developed at the University of Calabria and ICAR-CNR for designing and running distributed knowledge discovery applications on Grid environments.
Knowledge Discovery in Databases (KDD) employs a variety of software systems and tools to find useful patterns, models and trends in large volumes of data. In many scientific and commercial applications, it is necessary to perform the analysis of large data sets, maintained over geographically distributed sites, by using the computational power of distributed and parallel systems.
These techniques are investigated in the domain of Parallel and Distributed Knowledge Discovery (PDKD). In this area Grid technologies play a significant role in providing an effective computational support for knowledge discovery applications.
The Knowledge Grid is designed on top of computational Grid mechanisms provided by Grid environments such as Globus Toolkit and uses basic Grid services such as communication, authentication, information, and resource management to build more specific PDKD tools and services. The Knowledge Grid services are organized into two layers: Core K-Grid Layer , which is built on top of generic Grid services, and High-Level K-Grid Layer , which is implemented over the core layer.
The Knowledge Grid enables the collaboration of scientists that must mine data that are stored in different research centers as well as executive managers that must use a knowledge management system that operates on several data warehouses located in the different company establishments.
A visual software environment, named DIS3GNO, has been implemented to allow a user to: i) compose a distributed data mining workflow; ii) execute the workflow onto the Knowledge Grid; iii) visualize the results of the data mining task. DIS3GNO performs the mapping of the user-defined workflow to the conceptual model and submits it to the Knowledge Grid services, managing the overall computation in a way that is transparent to the user.
Publications
A detailed description as well as the system architecture of the Knowledge Grid can be found in the Publications section.
Related work
Another distributed data mining toolkit, designed and developed within the Gridlab research group, is Weka4WS, an extension of the open source Weka data mining suite. Using an existing, well established and widespread data mining software, has the advantage of letting data mining experts focus on the composition of their applications using a familiar tool, without having to learn a new environment or to learn complex tools and languages for the use and management of a Grid. More information about Weka4WS can be found following this link.
Contrary to Weka4WS, the Knowledge Grid, through its client application DI3GNO, allows the composition of abstract workflows, that is workflows whose nodes may be not completely specified. In this way, a user can concentrate on the application logic, without focusing on the actual datasets or data mining tool to be used: the Knowledge Grid services will take care of finding the resources that fit user specifications.
Installation
Software prerequisites
The Knowledge Grid requires Globus Toolkit 4.0.x (full installation) both on the server nodes and on the client nodes. Note that this is not a minimum requirement but a specific requirement: Globus Toolkit 4.2.x and later versions contain some updates to the web services specifications and in some other of its services which make them incompatible with the Knowledge Grid.
Since the full version of Globus Toolkit 4.0.x runs on Unix platforms (Linux included), the Knowledge Grid client and services can be currently installed only on those systems. The Knowledge Grid has been tested on Ubuntu 10.04.
To install Globus Toolkit 4.0.x here you have some useful links:
- Globus Toolkit 4.0.x Download
- GT 4.0.x Quickstart Guide
- Install Globus Toolkit 4.0.8 on Ubuntu 10.04 LTS
- Globus Toolkit 4.0.x troubleshooting
- Develop Globus grid services with Eclipse
Security prerequisites
The Knowledge Grid runs in a security context, and uses a gridmap authorization: that is only users that are listed in the service gridmap may invoke it. So in order to make the Knowledge Grid run properly the following prerequisites must be satisfied:
1. The Knowledge Grid user must hold a valid proxy certificate (in the X.509 format) with a given Distinguished Name (DN);
2. The file ‘/etc/grid-security/grid-mapfile’ on every server node must contain an entry to map the Knowledge Grid user to the ‘globus’ user at the computing node, for example:
"O=KGrid/OU=University of Calabria/CN=John Doe" globus
To know the DN of a user, log in as that user and run:
grid-proxy-info -identity
To check the grid-mapfile consistency run:
grid-mapfile-check-consistency
Server nodes
The following system variables must be set in your /etc/profile or /etc/bash.bashrc:
export JAVA_HOME=/usr/lib/jvm/jdk1.6.0_34 export ANT_HOME=/usr/share/ant export GLOBUS_LOCATION=/usr/local/globus-4.0.8 export GLOBUS_OPTIONS="-Xms256M -Xmx1024M" source $GLOBUS_LOCATION/etc/globus-user-env.sh export PATH=$PATH:$JAVA_HOME/bin:$ANT_HOME/bin:$GLOBUS_LOCATION/bin
Download the package containing Knowledge Grid services gars to /home/globus/ , extract its content and deploy the gars.
Download the package containing Knowledge Grid folders structure to /home/globus/ and extract its content there.
Client node
Download the DIS3GNO package and extract its content in a directory of your choice.
Configuration
-
currently the Knowledge Grid supports a star topology for its grid nodes network. The node with the EPMS service is considered the center of the star: on this node, edit the file /home/globus/kgrid/kds_neighbours and type in there the network addresses of all the nodes of the Knowledge Grid, each one on a separate line;
-
Edit the file /home/globus/kgrid/kmr/KDS_Registry of all the nodes of the Knowledge Grid and type in there the KDS addresses and the local path to your metadata, like in the following example:
kds://fully.qualified.hostname/data.xml /home/globus/kgrid/kmr/example.xml
Execution
Server nodes
As ‘root’ user, start the GridFTP by running:
$GLOBUS_LOCATION/sbin/globus-gridftp-server -p <port>
(where <port> is the desired port; if not specified the default 2811 port will be used)
As ‘globus’ user, start the globus container by running:
$GLOBUS_LOCATION/bin/globus-start-container -p <port>
(where <port> is the desired port; if not specified the default 8443 port will be used)
Client node
Enter the directory where you extracted the client package and run “dis3gno.sh”.
Troubleshooting
* OutOfMemoryException (at client side): most Java virtual machines only allocate a certain maximum amount of memory to run Java programs. Usually this is much less than the amount of RAM in your computer. With DIS3GNO you can extend the memory available for the virtual machine by running the ‘dis3gno.sh’ script passing as first argument the amount of RAM (in MB) you wish to use. For example running:
./dis3gno.sh 2048
will run DIS3GNO setting the maximum Java heap size to 2048MB.
* OutOfMemoryError (at server side): it is recommended to increase the maximum heap size of the JVM when running the container. By default on Sun JVMs a 64MB maximum heap size is used. The maximum heap size can be set using the -Xmx JVM option. For example if you want to set 2048MB as maximum heap size you need to run:
setenv GLOBUS_OPTIONS -Xmx2048M
* Gtk-WARNING **: Unable to locate theme engine in module_path: “pixmap” (at DIS3GNO startup): if you get this message running DIS3GNO on Ubuntu then run the following command:
sudo apt-get install gtk2-engines-pixbuf
* org.globus.common.ChainedIOException: Authentication failed [Caused by: Operation unauthorized (Mechanism level: Authorization failed. Expected “/CN=host/localhost” target but received “/O=KGrid/CN=host/fully.qualified.hostname”)]: open the file /home/globus/kgrid/kmr/KDS_Registry and make sure the KDS address contains the fully qualified hostname, like in the following example:
kds://fully.qualified.hostname/data.xml /home/globus/kgrid/kmr/example.xml
* the execution ends without any notification (i.e. the success dialog is not displayed as in Figure 5): make sure there is no interference by a firewall or NAT router that prevents notification delivery to the client. To avoid NAT router problems try adding in the /etc/hosts of each one of your server nodes the following entry:
x.x.x.x hostname fully.qualified.hostname
where x.x.x.x is the server public IP.
* starting DIS3GNO the following error message appears in the terminal:
Can't connect to X11 window server using ':0' as the value of the DISPLAY variable.
This happens when DIS3GNO is started from a terminal with a different user from the one logged in the graphical environment. Start DIS3GNO with the same user as the one logged in the graphical environment.
* java.lang.Exception: Error parsing file /home/globus/kgrid/kmr/filename.xml:
Change the owner of the /home/globus/kgrid/kmr directory and its content to globus by running:
sudo chown gloubus. -R /home/globus/kgrid/kmr
* For other troubleshooting about Globus Toolkit see Globus Toolkit 4.0.x troubleshooting.
Screenshots
 |
Figure 1: in order to ease the workflow composition and to allow a user to monitor its execution, each resource icon bears a symbol representing the status in which the corresponding resource is at a given time. When the resource status changes, as consequence of the occurrence of certain events, its status symbol changes accordingly. |
| ~ | |
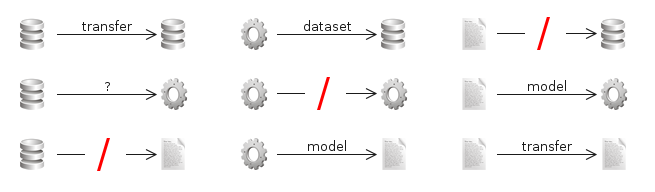 |
Figure 2: the nodes may be connected with each other through edges, establishing specific dependency relationships among them. When an edge is being created between two nodes, a label is automatically attached to it representing the kind of relationship between the two nodes. In most of the cases this relationship is strict but in one case (dataset-tool connection) requires further input from a user to be specified. |
| ~ | |
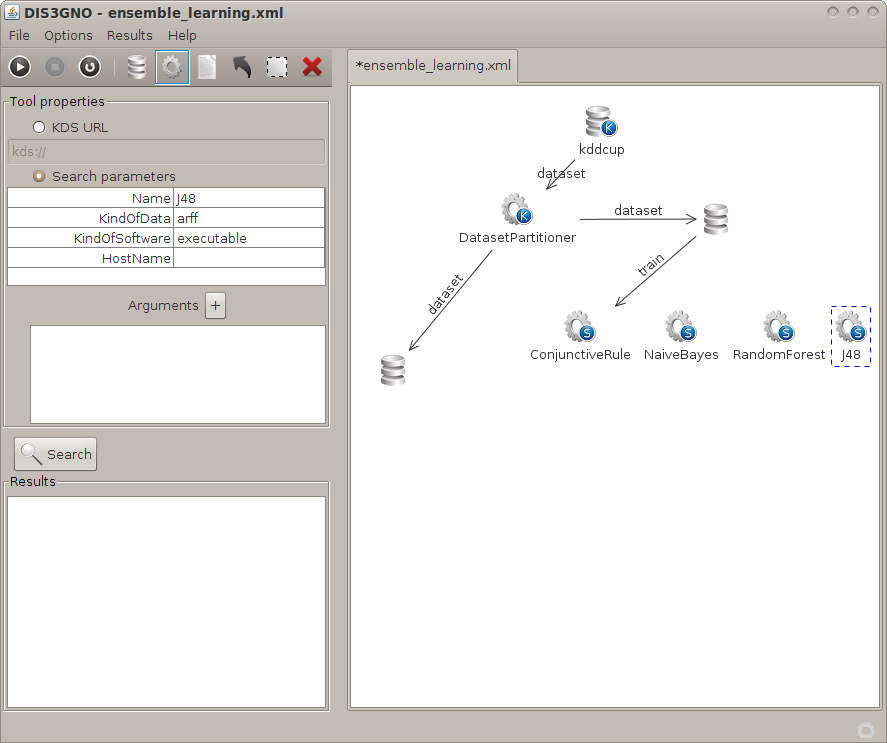 |
Figure 3: example of workflow composition: insertion and specification of an abstract tool resource; |
| ~ | |
 |
Figure 4: example of workflow composition: insertion of a labelled edge between dataset and voter. |
| ~ | |
 |
Figure 5: example of workflow termination: the success dialog displaying the overall execution time. |
| ~ | |
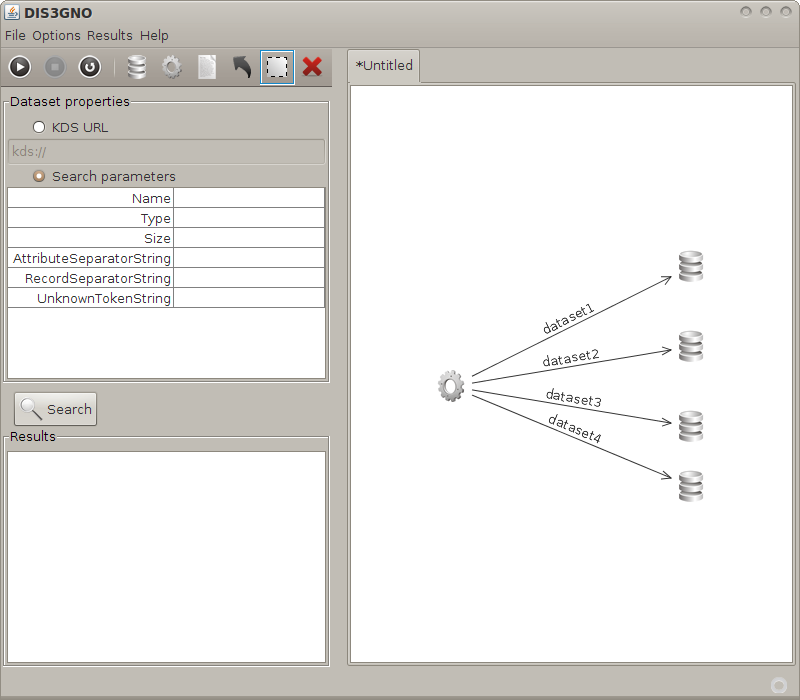 |
Figure 6: a tool node connected with multiple datasets. |
Changelog
Version 0.6 (Aug 31, 2012):
* in DIS3GNO, a success dialog is displayed at the end of the workflow execution displaying the overall execution time (see Figure 5);
* in DIS3GNO, the output edges connecting a tool node with multiple datasets now can be distinguished thanks to some index numbers appended to their labels (see Figure 6);
* error messages thrown in the services are now forwarded and displayed in DIS3GNO;
* in the RAEMS service, parallel data mining tasks are now executed on multiple nodes in a round robin fashion;
* grid nodes can be dinamically added at any time without having to restart the globus container;
* various bugfixes;
Version 0.5 (Feb 9, 2011):
* First release available to the public;
Download
The current Knowledge Grid packages (0.6, dated Aug 31, 2012) can be downloaded here:
- Binaries:
- Sources:
Copyright (C) 2005-2012 University of Calabria – Dept. of Electronics, Computer Science and Systems
This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 2 of the License, or (at your option) any later version.
How to cite
People
This project was designed and developed by Domenico Talia, Eugenio Cesario, Marco Lackovic and Paolo Trunfio.
For comments and suggestions please use the form below.